Optimizing a model for inference#
There are few ways to optimize a model for inference, some of them are basically a simplification of its graph:
-
find and remove redundant operations: for instance dropout has no use outside the training loop, it can be removed without any impact on inference; -
perform constant folding: meaning find some parts of the graph made of constant expressions, and compute the results at compile time instead of runtime (similar to most programming language compiler); -
kernel fusion: to avoid 1/ loading time, 2/ share memory to avoid back and forth transfers with the global memory and 3/ use optimal implementation of a series of operations. Obviously, it will mainly benefit to memory bound operations (like multiply and add operations, a very common pattern in deep learning), it’s called “kernel fusion”;
Another orthogonal approach is to use lower precision tensors, it may be FP16 float number or INT-8 quantization.
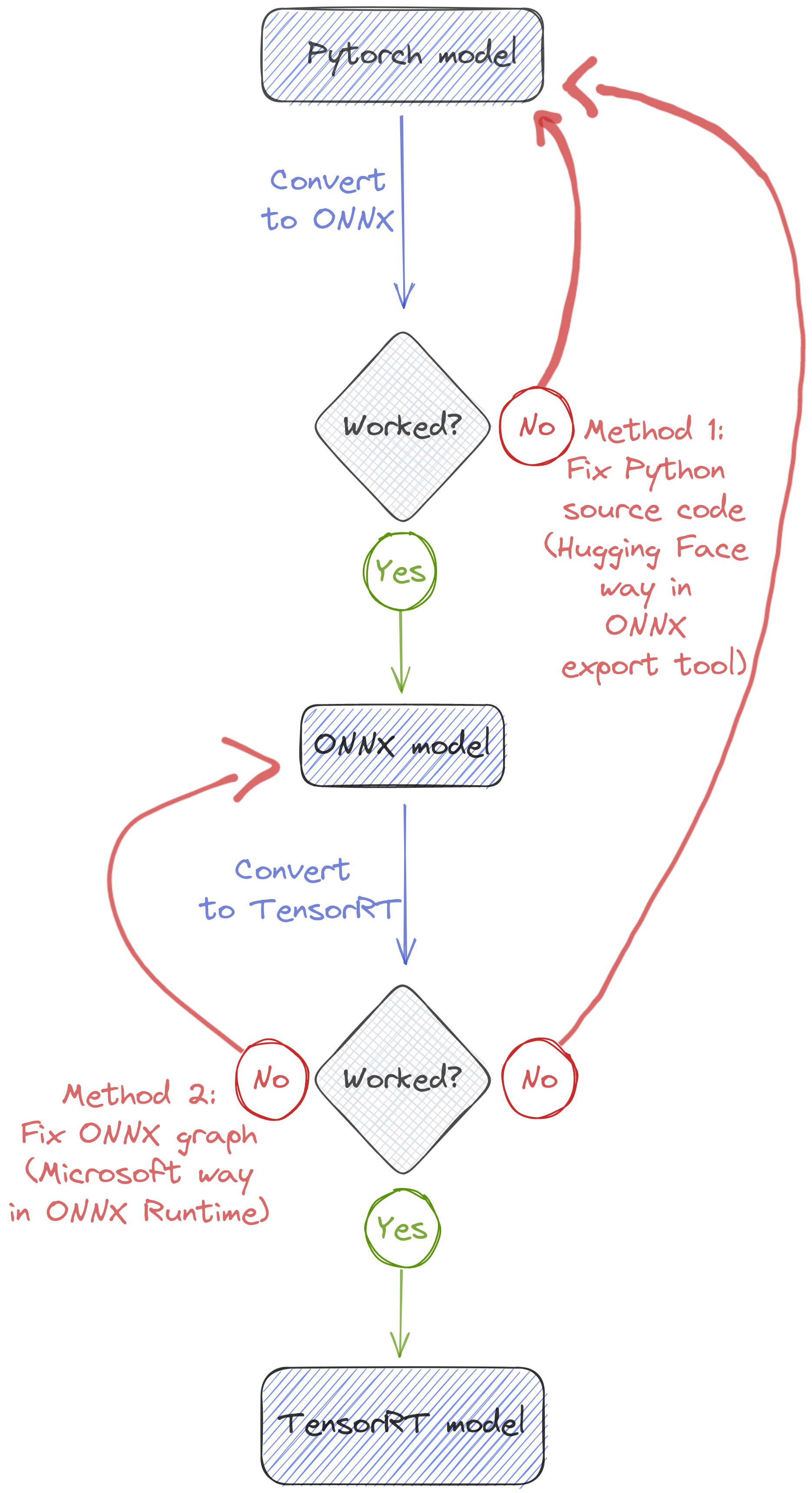
Attention
Mixed precision and INT-8 quantization may have an accuracy cost.
The reason is that you can't encode as much information in FP16 or INT-8 tensor that you can in FP32 tensor.
Sometimes you do not have enough granularity, some other times the range is not big enough.
When it happens, you need to modify the computation graph to keep some operators in full precision.
This library does it for mixed precision (for most models) and provide you with a simple way to do it for INT-8 quantization